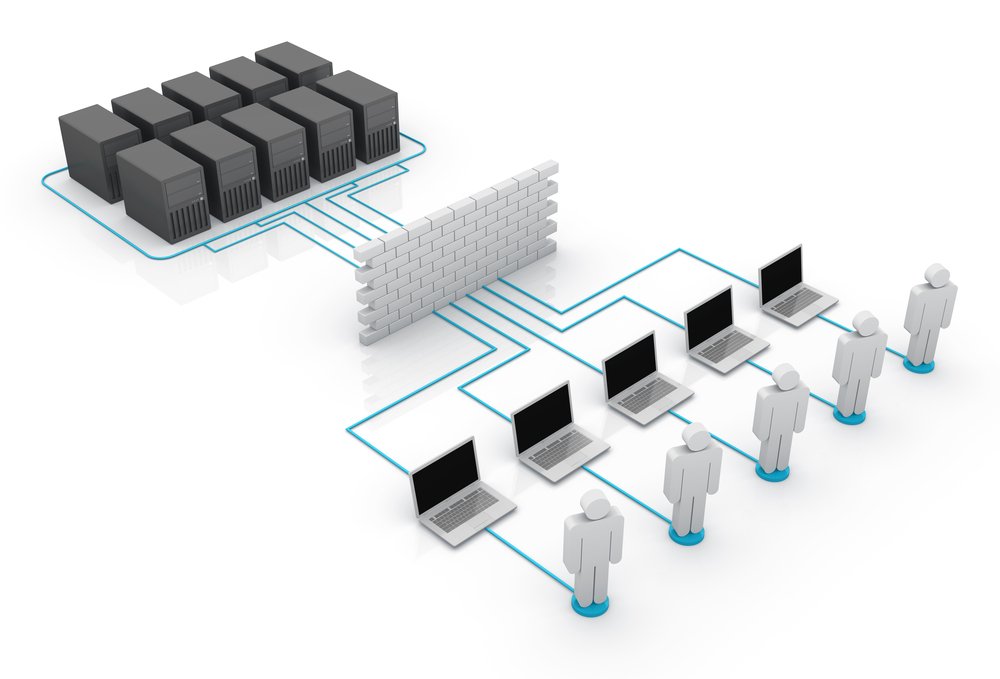
Hybrid Connectivity: On-Prem ↔ Cloud mit Routing- und Security-Blueprints ist für viele Unternehmen der pragmatischste Weg, moderne Cloud-Services zu nutzen, ohne bestehende Rechenzentrumslandschaften sofort abzulösen. In der Praxis entstehen hybride Umgebungen, weil Anwendungen, Datenbanken und Legacy-Systeme weiterhin On-Premises laufen, während neue Workloads, Analytics oder Managed Services in die Cloud wandern. Damit diese Welt zuverlässig funktioniert, braucht es mehr als nur „eine Leitung“ in die Cloud: Entscheidend sind ein sauberes Routing-Design, klar definierte Sicherheitszonen und wiederverwendbare Blueprints, die Betrieb, Skalierung und Auditierbarkeit ermöglichen. Wer Hybrid Connectivity strukturiert plant, reduziert Ausfallrisiken, vermeidet teure Fehlkonfigurationen und schafft die Grundlage für Zero-Trust-Ansätze, Segmentierung und Compliance. Der folgende Beitrag erklärt verständlich, wie Sie On-Prem ↔ Cloud-Konnektivität aufbauen, welche Routing-Patterns sich bewährt haben und wie Security-Blueprints aussehen, die in realen Umgebungen tragfähig sind.
Was Hybrid Connectivity in der Praxis bedeutet
Hybrid Connectivity beschreibt die kontrollierte, performante und sichere Vernetzung zwischen dem lokalen Netzwerk (On-Premises) und Cloud-Netzwerken (z. B. VPC/VNet) über definierte Pfade, Regeln und Sicherheitskontrollen. Häufige Ziele sind:
- Applikationsmigration in Etappen (z. B. Web-Tier in die Cloud, Datenbank vorerst On-Prem)
- Cloud-Bursting für Lastspitzen
- Zugriff auf Managed Services (z. B. Datenanalyse, Messaging, KI)
- Disaster Recovery in die Cloud
- Zentrale Identität und Policies über beide Welten hinweg
Damit das funktioniert, müssen Netzgrenzen eindeutig sein: Welche Subnetze dürfen miteinander sprechen? Welche Dienste müssen aus dem Internet erreichbar sein? Welche Datenflüsse sind verboten? Routing- und Security-Blueprints geben darauf wiederholbare Antworten.
Grundlagen: Routing, Namensauflösung und Adressierung
Bevor Sie über Firewalls und IPS-Regeln sprechen, müssen die Grundlagen stimmen: IP-Adressräume dürfen sich nicht überlappen, Routing muss deterministisch sein und DNS muss in beiden Richtungen zuverlässig funktionieren. Typische Stolpersteine sind überlappende RFC1918-Netze, „spontan“ vergebene Subnetze, uneinheitliche DNS-Zonen oder fehlende Reverse-Lookups bei Security-Tools.
IP-Planung ohne Overlaps
Ein sauberer IP-Plan ist ein Security- und Betriebsfaktor. Overlaps führen zu asymmetrischem Routing, NAT-Zwangslösungen und schwer nachvollziehbaren Ausfällen. Bewährt hat sich eine hierarchische Planung:
- Globaler Privatbereich (z. B. 10.0.0.0/8) in logisch getrennte Regionen/Standorte aufteilen
- Pro Cloud-Umgebung (Prod, Test, Dev) feste, nicht überlappende CIDRs reservieren
- Pro Anwendung/Zone Subnetze nach Funktion (Web, App, DB, Management) definieren
Wenn Overlaps historisch unvermeidbar sind, sollten Sie das als Ausnahme behandeln und die Komplexität bewusst in eine Transitional-Zone kapseln (z. B. per NAT-Gateway oder Proxy), statt den gesamten Traffic „irgendwie“ zu maskieren.
DNS als Teil des Connectivity-Designs
Hybride Umgebungen scheitern häufig nicht am Routing, sondern an Namensauflösung. Planen Sie früh:
- Split-Horizon-DNS für interne vs. externe Namen
- Forwarding/Conditional Forwarding zwischen On-Prem-Resolvern und Cloud-Resolvern
- Zonenhoheit (wer ist autoritativ für welche Zone?)
- Logging für DNS-Queries zur Fehlersuche und Security-Analysen
Viele Plattformen bieten hierzu Best Practices, etwa in den Netzwerkkonzepten der großen Hyperscaler. Als Einstieg helfen die Dokumentationen zu Amazon VPC und Azure Virtual Network.
Konnektivitätsoptionen: VPN, Dedicated Links und SD-WAN
Für On-Prem ↔ Cloud gibt es drei Grundrichtungen: Internet-basierte VPNs, dedizierte Leitungen und Overlay-Ansätze wie SD-WAN. In der Realität kombinieren viele Unternehmen mehrere Varianten (z. B. Dedicated Link als Primärpfad, VPN als Backup).
Site-to-Site-VPN: schnell startklar, aber begrenzt
IPsec-VPNs sind oft der erste Schritt. Vorteile: schneller Aufbau, vergleichsweise geringe Kosten, flexibel über Standorte hinweg. Grenzen: Durchsatz und Latenz hängen vom Internet ab, außerdem sind Skalierung und Monitoring anspruchsvoller. Für produktive, latenzkritische Workloads sollten Sie früh prüfen, ob ein VPN den Bedarf langfristig deckt oder nur als Übergang dient.
Dedicated Connectivity: stabil, performant, planbar
Dedizierte Verbindungen (z. B. AWS Direct Connect oder Azure ExpressRoute) bieten typischerweise stabilere Latenzen, höheren Durchsatz und klare SLAs. Gerade für datenintensive Workloads oder Compliance-Anforderungen (z. B. kontrollierter Datenpfad) sind sie häufig die bessere Wahl. Als Orientierung dienen die offiziellen Übersichten zu AWS Direct Connect und Azure ExpressRoute.
SD-WAN und Overlay: zentrale Steuerung, flexible Pfade
SD-WAN kann mehrere Leitungen (MPLS, Internet, 5G) bündeln und Pfade dynamisch wählen. In hybriden Architekturen ist das attraktiv, weil Sie Standorte standardisiert anbinden und Policies zentral verwalten. Wichtig ist, die Verantwortung sauber zu trennen: SD-WAN optimiert Pfade und QoS, ersetzt aber nicht automatisch Netzwerksegmentierung, Cloud-Native Security Controls oder ein sauberes Routing-Konzept.
Routing-Blueprints: bewährte Patterns für hybride Netze
Ein Routing-Blueprint ist ein wiederholbares Designmuster, das beschreibt, wie Datenpakete zwischen Zonen, Standorten und Cloud-Umgebungen laufen dürfen. Gute Blueprints minimieren Sonderfälle und machen Fehler sichtbar. Die folgenden Patterns sind in der Praxis besonders relevant.
Hub-and-Spoke: der Standard für Skalierung und Governance
Beim Hub-and-Spoke-Design existiert ein zentraler Hub (oder mehrere Hubs pro Region), über den Spokes (VPCs/VNets für Anwendungen/Teams) angebunden werden. Der Hub enthält typischerweise Shared Services: zentrale Firewalls, NAT, DNS-Forwarder, zentrale Logging- oder Security-Tools. Vorteile:
- Klare Kontrollpunkte für Security Inspection
- Skalierbarkeit durch standardisierte Spoke-Onboarding-Prozesse
- Trennung zwischen Plattform-Team (Hub) und Produkt-Teams (Spokes)
Wichtig: „Zentral“ darf nicht „Single Point of Failure“ bedeuten. Planen Sie Redundanz (mehrere Geräte/Instanzen, mehrere Verfügbarkeitszonen, mehrere Leitungen) und testen Sie Failover realistisch.
Transit/Backbone: Routing als Produkt
In größeren Umgebungen wird der Hub zu einem Transit-Netz, das als „Backbone“ fungiert. Hier werden Routen kontrolliert verteilt (z. B. über BGP), Policies versioniert und Änderungen wie Releases behandelt. Das steigert Qualität und reduziert Ad-hoc-Changes. Für Teams bedeutet das: Sie konsumieren Connectivity wie eine Plattformleistung, statt jedes Projekt neu zu verdrahten.
Segmentiertes East-West-Routing: Mikrosegmentierung statt flacher Netze
Hybride Umgebungen leiden oft an flachen Netzen („alles kann alles“). Besser ist ein segmentiertes East-West-Design: Spokes dürfen nur über definierte Services sprechen, sensible Zonen (z. B. Datenbanken, PCI, OT) sind strikt getrennt. Praktisch bedeutet das: Kein automatisches Transit-Routing zwischen Spokes, sondern kontrollierte Freigaben über zentrale Inspection oder Service-Endpoints.
Asymmetrisches Routing vermeiden
Ein Klassiker: Der Hinweg läuft über die zentrale Firewall, der Rückweg „findet“ eine Abkürzung. Ergebnis: Verbindungsabbrüche, fehlerhafte Stateful-Inspection, schwer debuggbare Incidents. Maßnahmen:
- Klare Route-Propagation-Regeln (wer kündigt welche Routen an?)
- Stateful-Firewalls nur dort einsetzen, wo der gesamte Flow garantiert durchläuft
- Policy-Based Routing sparsam und dokumentiert verwenden
- Flow-Logs in Cloud und On-Prem korrelieren
Security-Blueprints: Zonen, Kontrollen und Prinzipien
Security-Blueprints definieren, wie Sicherheit in der hybriden Konnektivität umgesetzt wird: Wo wird gefiltert? Wie wird segmentiert? Welche Identitäten dürfen was? Ein Blueprint ist kein einzelnes Produkt, sondern eine Kombination aus Prinzipien, Policies und technischen Controls.
Zero Trust als Leitlinie (nicht als Buzzword)
Im Hybrid-Setup ist „intern = vertrauenswürdig“ nicht mehr tragfähig. Zero Trust heißt in der Praxis: Identität, Geräte- und Kontextsignale sowie minimale Berechtigungen bestimmen den Zugriff. Netzsegmentierung bleibt wichtig, wird aber ergänzt durch starke Identitätskontrollen, MFA, Conditional Access und servicebasierte Freigaben. Eine gute Orientierung bietet das NIST-Dokument zur Zero-Trust-Architektur.
Sicherheitszonen und Trust Boundaries
Definieren Sie Zonen, die in beiden Welten gleich verstanden werden. Ein praxisnahes Modell ist:
- Edge/DMZ: Internet-exponierte Komponenten, WAF, DDoS-Schutz, Reverse Proxies
- App-Zone: Anwendungslogik, APIs, Container/VMs
- Data-Zone: Datenbanken, Storage, Secrets, Schlüsselverwaltung
- Management-Zone: Bastion, Admin-Workstations, Deployment-Systeme
- Shared Services: DNS, Monitoring, Logging, Patch/Repo-Services
Jede Zone erhält klare Ein- und Ausgänge. Besonders die Management-Zone sollte strikt isoliert sein und nur über abgesicherte Wege erreichbar sein (z. B. Bastion/Privileged Access Workstations).
Ingress und Egress: Kontrolle an den richtigen Stellen
Viele Security-Probleme entstehen durch unkontrollierten Outbound-Traffic. Ein Egress-Blueprint umfasst typischerweise:
- Zentrale oder dezentrale Egress-Gateways (je nach Skalierung und Latenzanforderung)
- DNS- und HTTP(S)-Kontrollen (Filter, Kategorien, Threat Intelligence)
- Restriktive Default-Policies („deny by default“ für unbekannte Ziele)
- Ausnahmen als Code (Change-Management, Reviews, Ablaufdaten)
Für Ingress gilt: Exponieren Sie möglichst wenig. Nutzen Sie WAF, TLS-Termination, Rate Limiting und starke Authentifizierung. In der Cloud sind Managed-Dienste oft sinnvoll, weil sie Skalierung und Patching abnehmen, solange sie korrekt konfiguriert werden.
Network Security Controls: Cloud-Native plus zentrale Inspection
Ein robustes Security-Design kombiniert Cloud-Native Controls (Security Groups/NSGs, NACLs, Private Endpoints, Routing Tables) mit zentralen Kontrollen dort, wo sie nötig sind (z. B. Next-Gen-Firewalls im Hub). Wichtig ist die Rollenverteilung:
- Workload-nahe Controls (z. B. Security Groups/NSGs) setzen minimale Kommunikation direkt an der Quelle/Zielinstanz durch.
- Zentrale Controls (z. B. Firewall-Cluster) bieten Inspection, Protokollierung und konsistente Governance für kritische Flows.
- Service-spezifische Controls (z. B. IAM-Policies, KMS, Secrets Manager) sichern Datenzugriff unabhängig vom Netzpfad.
Blueprint für Verfügbarkeit: Redundanz, Failover, Observability
Hybrid Connectivity ist ein kritischer Pfad. Ein Ausfall trifft oft mehrere Anwendungen gleichzeitig. Deshalb gehört Hochverfügbarkeit nicht „später“ dazu, sondern ist Teil des Blueprints.
Redundanz auf mehreren Ebenen
- Physisch/Provider: mindestens zwei unabhängige Leitungen oder Provider, getrennte Trassen wenn möglich
- Geräte/Endpoints: redundante Router/Firewalls, aktive/aktive oder aktive/passive Designs
- Cloud-seitig: mehrere Availability Zones, multiple Tunnels/Verbindungen
- Routing: dynamisches Routing (z. B. BGP) mit sauberen Präferenzen und Health-Checks
Testen Sie Failover nicht nur im Lab: Simulieren Sie Leitungsunterbrechungen, Geräteausfälle und fehlerhafte Routenankündigungen, und prüfen Sie, ob Anwendungen stabil bleiben.
Observability: Logs, Metriken und Tracing für Netzwerkpfade
Ohne Sichtbarkeit wird Hybrid Connectivity schnell zu „Blackbox-Netzwerk“. Ein Blueprint sollte festlegen:
- Flow Logs in Cloud-Netzen und Firewall-Logs im Hub
- Metriken zu Latenz, Jitter, Paketverlust, Tunnelstatus, Throughput
- Alarmierung nach Service-Impact (nicht nur „Tunnel down“)
- Korrelationsfähigkeit über eine zentrale Log-Plattform (Zeitstempel, IDs, Tags)
Für generelle Leitlinien zur Absicherung und Überwachung von Systemen kann außerdem das CIS Controls Framework als Orientierung dienen, insbesondere bei Logging, Zugriffskontrolle und Konfigurationsmanagement.
Blueprint für Betrieb und Governance: Standards, IaC und Change-Prozesse
Hybride Netze wachsen schnell. Ohne Standards entsteht Konfigurationsdrift: manuelle Änderungen, unterschiedliche Firewall-Regeln je Projekt, unklare Verantwortlichkeiten. Ein Betriebs-Blueprint bringt Ordnung.
Infrastructure as Code für Netzwerk und Security
Nutzen Sie IaC (z. B. Terraform, Bicep, CloudFormation) für wiederholbare Deployments. Das betrifft nicht nur Subnetze, sondern auch Routing Tables, Security Groups/NSGs, Firewall-Policies, Private Endpoints und DNS-Konfigurationen. Vorteile:
- Reviewbarkeit über Pull Requests
- Versionierung mit nachvollziehbaren Changes
- Reproduzierbarkeit in mehreren Umgebungen (Dev/Test/Prod)
- Policy Enforcement über Guardrails (z. B. Richtlinien, Linter, OPA)
Policy- und Rollenmodell: Wer darf Routen ändern?
Routing und zentrale Security sind hochkritisch. Legen Sie ein Rollenmodell fest:
- Plattform-/Netzwerkteam: Hub/Transit, zentrale Firewalls, Route Propagation
- Applikationsteams: Workload-nahe Regeln, Security Groups/NSGs innerhalb ihrer Spokes
- Security-Team: Baselines, Audit-Anforderungen, Ausnahmeregeln, Threat-Modeling
Wichtig ist, dass Ausnahmen dokumentiert und befristet sind. Ein häufiger Best Practice ist ein „Exception Register“ mit Owner, Risiko, Kompensation und Ablaufdatum.
Typische Use Cases und passende Connectivity-Patterns
Die beste Architektur hängt vom Datenfluss ab. Einige häufige Szenarien und passende Muster:
- Web-App mit On-Prem-Datenbank: Hub-and-Spoke, strikte Segmentierung, nur DB-Ports Richtung Data-Zone, bevorzugt private Verbindungen statt Internet.
- Data Analytics in der Cloud: Dedicated Link oder performantes VPN, Egress-Kontrolle, Private Endpoints zu Storage/DB-Services, klare Datenklassifizierung.
- Shared Identity und zentrale Services: Transit/Backbone, DNS-Forwarding, Management-Zone isoliert, Logging zentralisiert.
- DR/Backup in die Cloud: Bandbreitenplanung, verschlüsselte Datenpfade, getrennte Accounts/Subscriptions, regelmäßige Restore-Tests.
Checkliste für den Start: Routing- und Security-Blueprint kompakt umsetzbar
- IP-Plan erstellen, Overlaps vermeiden oder sauber kapseln
- DNS-Strategie definieren (Zonenhoheit, Forwarding, Logging)
- Konnektivitätsform wählen (VPN, Dedicated, SD-WAN) und Backup-Pfad planen
- Routing-Pattern festlegen (Hub-and-Spoke/Transit) und asymmetrisches Routing ausschließen
- Sicherheitszonen und Trust Boundaries definieren (inkl. Management-Zone)
- Ingress/Egress-Blueprint mit restriktiven Default-Policies aufsetzen
- Observability verbindlich machen (Flow Logs, Metriken, Alarmierung)
- IaC-Standard und Review-Prozess für Netzwerk/Security etablieren
- Failover-Tests und Chaos-Tests für Konnektivität einplanen
- Ausnahmen dokumentieren, befristen und regelmäßig prüfen
Cisco Netzwerkdesign, CCNA Support & Packet Tracer Projekte
Cisco Networking • CCNA • Packet Tracer • Network Configuration
Ich biete professionelle Unterstützung im Bereich Cisco Computer Networking, einschließlich CCNA-relevanter Konfigurationen, Netzwerkdesign und komplexer Packet-Tracer-Projekte. Die Lösungen werden praxisnah, strukturiert und nach aktuellen Netzwerkstandards umgesetzt.
Diese Dienstleistung eignet sich für Unternehmen, IT-Teams, Studierende sowie angehende CCNA-Kandidaten, die fundierte Netzwerkstrukturen planen oder bestehende Infrastrukturen optimieren möchten. Finden Sie mich auf Fiverr.
Leistungsumfang:
-
Netzwerkdesign & Topologie-Planung
-
Router- & Switch-Konfiguration (Cisco IOS)
-
VLAN, Inter-VLAN Routing
-
OSPF, RIP, EIGRP (Grundlagen & Implementierung)
-
NAT, ACL, DHCP, DNS-Konfiguration
-
Troubleshooting & Netzwerkoptimierung
-
Packet Tracer Projektentwicklung & Dokumentation
-
CCNA Lern- & Praxisunterstützung
Lieferumfang:
-
Konfigurationsdateien
-
Packet-Tracer-Dateien (.pkt)
-
Netzwerkdokumentation
-
Schritt-für-Schritt-Erklärungen (auf Wunsch)
Arbeitsweise:Strukturiert • Praxisorientiert • Zuverlässig • Technisch fundiert
CTA:
Benötigen Sie professionelle Unterstützung im Cisco Networking oder für ein CCNA-Projekt?
Kontaktieren Sie mich gerne für eine Projektanfrage oder ein unverbindliches Gespräch. Finden Sie mich auf Fiverr.










