


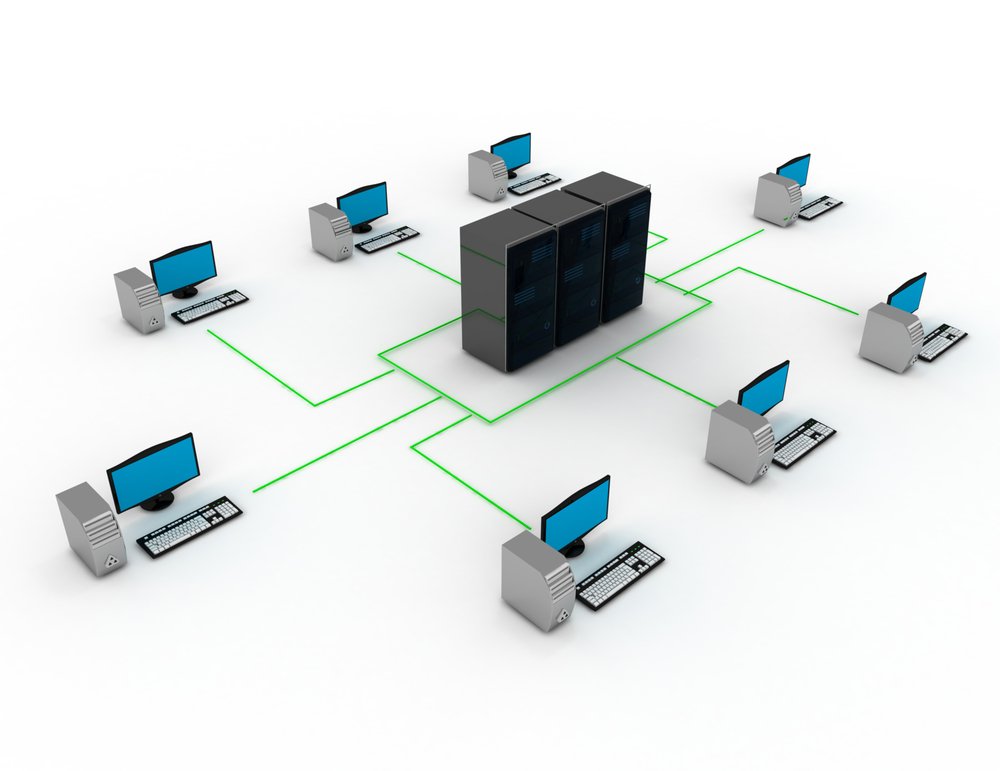
Spine-Leaf Design in Rechenzentren ist heute der De-facto-Standard, wenn es um skalierbare Ost-West-Kommunikation, planbare Latenz und hohe Kapazität geht. Während klassische Drei-Schichten-Modelle (Core/Distribution/Access) in vielen Umgebungen historisch gewachsen sind, adressiert die Spine-Leaf-Architektur gezielt die Realität moderner Workloads: Microservices, Container-Plattformen, verteilte Datenbanken, Storage-Replikation und stark variierende Traffic-Mixe. Der zentrale Vorteil liegt in der Vorhersagbarkeit: Jeder Leaf hat eine definierte Anzahl an Uplinks zu den Spines, Pfadlängen bleiben konstant, ECMP ermöglicht Load Sharing und Wachstum erfolgt modular. Gleichzeitig wird Spine-Leaf im Alltag oft falsch geplant – etwa wenn Oversubscription-Ratios „aus dem Bauch“ gewählt werden, Latency Budgets nicht in Designentscheidungen übersetzt werden oder Scale-Grenzen (Control Plane, FIB-Ressourcen, Overlay-Standards) erst im Betrieb auffallen. Dieser Artikel zeigt, wie Sie Spine-Leaf Design in Rechenzentren belastbar planen: Kapazitätsmodelle, Latenzbudgets und Skalierung werden als Design-Inputs behandelt, inklusive praktischer Patterns, Messmethoden und typischer Fallstricke.
Was Spine-Leaf eigentlich ist: Ein Kapazitäts- und Pfadmodell
Spine-Leaf ist weniger ein „Diagramm“ als ein klares Modell für Pfade und Kapazität. Leafs stellen die Access-Schicht dar (Server/Hypervisor/ToR), Spines bilden die gleichrangige Aggregationsschicht. Jeder Leaf ist mit jedem Spine verbunden, wodurch eine nahezu konstante Hop-Anzahl zwischen Leafs entsteht. Das ist für Latenz und Fehlersuche entscheidend: Der Pfad ist in der Regel Leaf → Spine → Leaf, unabhängig davon, wo die Workloads liegen.
- Konstante Pfadlänge: planbare Latenz, weniger „Überraschungspfade“ als in mehrstufigen Designs.
- ECMP als Normalfall: mehrere gleichwertige Pfade ermöglichen Load Sharing und Redundanz.
- Modulares Wachstum: Leafs hinzufügen skaliert Ports und Kapazität; Spines definieren die Fabric-Größe.
- Failure Domains: Ausfälle lassen sich entlang von Leafs, Spines, Pods und Services schneiden.
Kapazität planen: Oversubscription, Headroom und echte Traffic-Profile
Die wichtigste Designfrage in Spine-Leaf ist nicht „welche Switches“, sondern: Welche Oversubscription ist akzeptabel, und welche Lastprofile sind realistisch? Moderne DC-Traffic-Muster sind oft burstig und enthalten wenige große Elephant Flows (Backup, Replikation, Datenpipelines) sowie viele kleine Mice Flows (Microservices). Ein belastbares Kapazitätsmodell berücksichtigt daher Perzentile, Failover-Zustände und Queueing, nicht nur Durchschnittsauslastung.
Oversubscription richtig definieren
Oversubscription beschreibt das Verhältnis aus Downlink-Kapazität (zu Servern) und Uplink-Kapazität (zu Spines). Ein einfaches Beispiel: 48×25G Downlinks und 6×100G Uplinks ergeben 1.200 Gbit/s Downlink zu 600 Gbit/s Uplink, also 2:1 Oversubscription. Das ist nicht automatisch „gut“ oder „schlecht“ – es hängt vom Workload-Mix ab.
- Compute-lastige Workloads: oft niedrigere Ost-West-Auslastung, höhere Oversubscription tolerierbar.
- Storage-/Daten-lastige Workloads: hohe Ost-West-Last, geringere Oversubscription sinnvoll.
- Container/Microservices: viele Ost-West-Calls, Traffic kann sprunghaft wachsen, Reserven wichtiger.
Headroom im Failover ist Pflicht
Spine-Leaf wird häufig im Normalbetrieb dimensioniert, nicht im N-1-Betrieb. Dabei ist N-1 der relevante Zustand: Ein Uplink fällt aus, ein Spine ist weg, ein Leaf hat Degradation. Wenn die Fabric dann in Überlast gerät, steigt Jitter, Drops nehmen zu, und Anwendungen wirken „instabil“. Ein professionelles Design plant explizit:
- N-1 Uplink: Leaf-Uplinks so dimensionieren, dass ein Ausfall nicht sofort Queues füllt.
- N-1 Spine: Wenn ein Spine ausfällt, muss die verbleibende Fabric den Lastshift tragen.
- Elephant-Flow-Reserve: Einzelne große Flows dürfen nicht jeden Failover in einen Hotspot verwandeln.
Latency Budgets: Latenz als harte Architekturgröße
Latenz ist im Rechenzentrum nicht nur „schnell“ oder „langsam“, sondern ein Budget, das sich aus mehreren Beiträgen zusammensetzt: Switch-Fabric, Queueing, SerDes/Transceiver, Kabelstrecken und – oft unterschätzt – aus Security-/Service-Chaining (z. B. Hairpinning über zentrale Gateways). Spine-Leaf hilft, den Routing-Pfad konstant zu halten. Die tatsächliche Latenz hängt jedoch stark von Queueing und Lastzuständen ab.
Ein Latency Budget strukturieren
- Base Latency: minimale Verzögerung bei leerem Netz (Switching + Optik).
- Queueing Delay: Verzögerung durch Warteschlangen unter Last; meist der dominante Anteil.
- Overlay-Overhead: Encapsulation (z. B. VXLAN) beeinflusst weniger die Latenz als die MTU-Planung, kann aber indirekt Drops erzeugen.
- Service-Chaining: zusätzliche Hops durch Firewalls/Proxies/Load Balancer können Budgets sprengen.
Für latenzkritische Anwendungen lohnt es sich, Zielwerte als Perzentile zu betrachten (z. B. P95/P99), nicht als Mittelwert. Ein Netzwerk kann im Durchschnitt „schnell“ sein und trotzdem P99-Latenzspitzen erzeugen, die Microservices oder Datenbanken destabilisieren.
Scale: Welche Grenzen Spine-Leaf wirklich hat
Spine-Leaf skaliert gut, aber nicht unbegrenzt. Die Grenzen liegen selten in der Topologie, sondern in Ressourcen und Betriebsmodellen: Anzahl der Leafs, Routing/Overlay-State, FIB-Tabellen, Multihoming-Modelle, Telemetrie-Last und die Fähigkeit, Standards konsistent auszurollen.
- Port-Scale: Spines bestimmen, wie viele Leafs in einer Fabric sinnvoll sind (Portzahl und Uplink-Anforderungen).
- Control Plane Scale: BGP/IGP Sessions, Update-Rate bei Flaps, CPU-Headroom für Convergence.
- FIB/TCAM-Ressourcen: Anzahl Routen, EVPN-MAC/IP-Entries, Policies, ACLs.
- Overlay-Scale: Anzahl VNIs/VRFs, MAC-Mobility, ARP/ND-Suppression, Route Targets.
- Operations-Scale: Automatisierung, Template-Standardisierung, Drift-Kontrolle, Rollout-Wellen.
Underlay-Design: Stabilität und ECMP als Fundament
Im Spine-Leaf ist das Underlay die Lebensader. Ein instabiles Underlay macht jedes Overlay und jede Applikation unzuverlässig. Deshalb sollte das Underlay bewusst „langweilig“ sein: klare IGP- oder BGP-Underlay-Standards, BFD dort, wo es sinnvoll ist, und Guardrails gegen Flaps.
- ECMP-Design: Gleichwertige Pfade sind Standard; Hashing, Elephant Flows und Failover-Last müssen berücksichtigt werden.
- Konvergenz als Ziel: Konvergenzzeiten pro Domäne definieren und testen, statt Timer zu raten.
- Failure Domains: Pods oder Fabrics so schneiden, dass ein Fehler nicht das gesamte DC trifft.
- MTU-Baseline: Reserven für Encapsulation und Jumbo-Frames, mit Tests gegen stille Drops.
Für die theoretische Einordnung von Multipath-Auswahl und deren Trade-offs sind RFC 2991 und RFC 2992 hilfreiche Referenzen.
Overlay-Design: EVPN/VXLAN als gängiges Pattern
In vielen Rechenzentren wird Spine-Leaf mit EVPN/VXLAN kombiniert, um Segmente und Mandanten logisch abzubilden. Das Overlay liefert Flexibilität, bringt aber zusätzliche Scale- und Operability-Anforderungen. Ein belastbares Design setzt auf klare Standards für VNIs/VRFs, Route Targets, Anycast Gateway und Multihoming.
- VXLAN als Data Plane: Kapselung von L2/L3 über IP; Grundlage in RFC 7348.
- EVPN als Control Plane: Verteilung von MAC/IP-Reachability über BGP; Grundlagen in RFC 7432.
- Flooding reduzieren: ARP/ND-Suppression und kontrolliertes Learning senken Unknown-Traffic.
Hotspots und Microbursts: Warum „viel Bandbreite“ nicht automatisch stabil ist
Spine-Leaf-Designs können enorme Gesamtbandbreite bereitstellen und trotzdem punktuell überlasten. Ursache sind häufig ECMP-Hotspots, Microbursts und Elephant Flows. Diese Effekte werden oft erst sichtbar, wenn Anwendungen unter Last „flattern“. Professionelles Design integriert deshalb Traffic-Profile, QoS und Observability von Anfang an.
- Elephant Flows: Backup und Replikation brauchen Zeitfenster, QoS oder separate Klassen.
- Hash-Entropie: NAT oder zentrale Gateways können Entropie reduzieren und Hotspots erzeugen.
- Queue-Telemetrie: Drops sind oft der frühe Indikator, nicht die reine Auslastung.
- Resilient Hashing: Wo verfügbar, begrenzt es Flow-Migration bei Failover und reduziert Burst-Drops.
Resilienz und Wartbarkeit: Spine-Leaf als „Produkt“ betreiben
Ein Spine-Leaf-Design ist nur dann langfristig erfolgreich, wenn es wartbar bleibt. Das betrifft nicht nur Firmware-Updates, sondern auch Standards, Tests und Rollouts. In großen DCs ist Change der häufigste Ausfalltreiber, daher müssen Wartungsabläufe und Rollback-Strategien integraler Bestandteil der Architektur sein.
- Staged Rollouts: Pilot-Leafs, dann Wellen, dann breite Ausrollung; so wird der Change-Blast-Radius begrenzt.
- Golden Configs: Templates und Baselines reduzieren Drift und machen Fehlersuche reproduzierbar.
- Testkatalog: Failover-, Degradation- und Maintenance-Tests mit klaren Abnahmekriterien.
- Operational Acceptance: Runbooks, Dashboards, Alarmierung und Ownership sind definiert.
Observability: Ohne Telemetrie wird Scale zum Risiko
Mit wachsender Fabric steigt die Notwendigkeit, Zustände schnell zu erkennen und zuzuordnen: Welche Links droppen? Welche Leafs sind Hotspots? Welche VNIs erzeugen Flooding? Welche Spines sind überlastet? Ein modernes Spine-Leaf-Setup sollte daher Observability-by-Design verankern.
- Device Telemetry: Interface-Errors, Drops, Queue-Stats, ECMP-Group-Changes, BGP/IGP-Events.
- Flow-Daten: Traffic-Mix, Elephant Detection, Ost-West-Verhältnisse, Hotspot-Ursachen.
- End-to-End-Probes: Latenz/Jitter/Loss pro kritischem Pfad und Serviceklasse.
- Zeitbasis: NTP als Voraussetzung für Korrelation und forensische Analysen.
Wenn Sie Servicequalität als Ziel definieren, können SLOs helfen, Architektur und Betrieb zu verbinden. Eine gut verständliche Grundlage dafür liefern die SRE-Ressourcen.
Praktische Design Patterns für Spine-Leaf in Rechenzentren
- Pod-basiertes Scaling: Mehrere Fabrics/Pods statt einer riesigen Fabric, um Failure Domains zu begrenzen und Upgrades planbarer zu machen.
- Layer-3-to-the-Host (wo sinnvoll): Reduziert Layer-2-Failure Domains, kann aber Anforderungen an Host-/Hypervisor-Integration erhöhen.
- Anycast Gateway im Overlay: Stabiler Default-Gateway-Ansatz für Workloads, reduziert unnötige Hairpins.
- Elephant-Flow-Separation: Storage/Backup/Replikation in definierte Klassen oder Netze, um Hotspots zu vermeiden.
- Resilient Hashing + Headroom: Kombination aus stabiler Hash-Verteilung und N-1-Kapazität für sauberes Failover.
Checkliste: Spine-Leaf Design belastbar definieren
- Kapazitätsmodell erstellt: Oversubscription pro Rack/Leaf definiert, Traffic-Profile und Elephant Flows berücksichtigt.
- N-1 geplant: Uplink-/Spine-Ausfallzustände dimensioniert, Headroom und Peak-Perzentile geprüft.
- Latency Budget definiert: Base Latency und Queueing als Perzentile betrachtet, Service-Chaining-Effekte eingeplant.
- Scale-Grenzen bewertet: Control Plane, FIB/TCAM, Overlay-State, Multihoming-Modelle, Automatisierungsfähigkeit.
- Underlay stabil: ECMP-Design, Konvergenzziele, BFD/IGP-Guardrails, MTU-Tests.
- Overlay-Standards: EVPN/VXLAN-Parameter (VNIs/VRFs/RTs), Anycast Gateway, Flooding-Reduktion.
- Observability vollständig: Queue-Telemetrie, Flow-Daten, End-to-End-Probes, Zeitbasis.
- Wartbarkeit eingebaut: Staged Rollouts, Golden Configs, Testkatalog, Runbooks und Rollbacks.
Cisco Netzwerkdesign, CCNA Support & Packet Tracer Projekte
Cisco Networking • CCNA • Packet Tracer • Network Configuration
Ich biete professionelle Unterstützung im Bereich Cisco Computer Networking, einschließlich CCNA-relevanter Konfigurationen, Netzwerkdesign und komplexer Packet-Tracer-Projekte. Die Lösungen werden praxisnah, strukturiert und nach aktuellen Netzwerkstandards umgesetzt.
Diese Dienstleistung eignet sich für Unternehmen, IT-Teams, Studierende sowie angehende CCNA-Kandidaten, die fundierte Netzwerkstrukturen planen oder bestehende Infrastrukturen optimieren möchten. Finden Sie mich auf Fiverr.
Leistungsumfang:
-
Netzwerkdesign & Topologie-Planung
-
Router- & Switch-Konfiguration (Cisco IOS)
-
VLAN, Inter-VLAN Routing
-
OSPF, RIP, EIGRP (Grundlagen & Implementierung)
-
NAT, ACL, DHCP, DNS-Konfiguration
-
Troubleshooting & Netzwerkoptimierung
-
Packet Tracer Projektentwicklung & Dokumentation
-
CCNA Lern- & Praxisunterstützung
Lieferumfang:
-
Konfigurationsdateien
-
Packet-Tracer-Dateien (.pkt)
-
Netzwerkdokumentation
-
Schritt-für-Schritt-Erklärungen (auf Wunsch)
Arbeitsweise:Strukturiert • Praxisorientiert • Zuverlässig • Technisch fundiert
CTA:
Benötigen Sie professionelle Unterstützung im Cisco Networking oder für ein CCNA-Projekt?
Kontaktieren Sie mich gerne für eine Projektanfrage oder ein unverbindliches Gespräch. Finden Sie mich auf Fiverr.